Indexers
If you're just looking for API docs for a hosted indexer, here is the one from TzKT, and here is the one from TzStats
What is an indexer ?
A block explorer, or an app that tracks activity on the blockchain, is typically made of:
- an indexer that is a node operator that extracts the on-chain data and stores it in a database
- an API that queries the database
- a frontend that displays the data
Since the on-chain data is already in the database of the node itself, why is an indexer needed? The indexer is relevant because it optimizes the way a node stores data. The purpose is to provide very quick access to blockchain data according to some specific criteria related to a given address.
So, the indexer is the part of the explorer that fetches the raw data from the node, then processes it and stores it in the database in an efficient way. They simplify querying and searching through blockchain data. Almost any decentralized application uses indexers, and if you want to build your dApp, chances are you’ll need to use them too.
TzKT
For instance, TzKT is a lightweight Tezos blockchain indexer with an advanced API created by Baking Bad.The indexer fetches raw data from the Tezos node, then processes it and stores it in the database in such a way as to provide effective access to the blockchain data. For example, getting operations by hash, getting all operations of the particular account, or getting detailed baking rewards, etc. None of this can be accessed via node RPC, but TzKT indexer makes this data (and much more) available.
You can install or build it, and configure it for the testnet.
To work with the TzKT API you can use this public endpoint.
Traditional Blockchain Explorer Backends
Indexers are node operators. The ETL extract, transform and load data into the SQL database by mapping the data into a pre-defined schema of tables with referential integrity in order to provide indexing and query processing services via the API.
- A Tezos Node is the heart of the blockchain, it manages the protocol.
- ETL stands for extract, transform, and load. The process of ETL plays a key role in data integration strategies. ETL allows businesses to gather data from multiple sources and consolidate it into a single, centralized location.
- API is the acronym for Application Programming Interface, which is a software intermediary that allows two applications to talk to each other.
Focus on BlockWatch Indexer (TzIndex)
The Blockwatch Indexer TzIndex is used for the TzStats explorer.
The Blockwatch indexer replaces the slow and expensive SQL datastore with a high-performance columnar database that allows for extremely fast analytical queries.
Columnar database is a column-oriented storage for databases. It is optimized for fast retrieval of data columns, for example for analytical applications. It significantly reduces the overall disk I/O requirements and limits the amount of data you need to load from the disk.
It's a custom-made database for blockchain analytics. Avoiding the storage bottleneck allows for more complex data processing.
Storage bottleneck is a situation where the flow of data gets impaired or stopped completely due to bad performance or lack of resources.
State updates happen at each block, which means all the balance updates are always verified, and the indexer will follow chain reorganizations in real-time.
A simple explanation of how indexers work
Understanding indexers is easy if we use a library as an example. There are thousands of books on the shelves in the library. They are usually sorted by genre and authors' names. The reader will quickly find the stand with novels or gardening books.
But let's say the reader wants to find something specific: a poem about an acacia tree, a story about a gas station architect, or all the books written in 1962. They will have to check all the books in the library until they come across what they are looking for.
The librarian got themselves ready for such visitors and compiled a special database. He wrote down the details of each book in separate indexes. For example, one index would list all the names of the characters of every book in alphabetical order and the name of the book where they appear. The second index will contain the key events, and the third—unique terms like “horcruxes” or “shai-hulud,” etc. The librarian can make as many indexes as he needs to simplify the search for a specific book.
Now let’s return to the blockchain. To find a transaction by its hash or by the address of the caller, you will have to check every transaction in every block. The best way out is to create a separate database with all the contents of the blockchain with pointers to search for information on specific queries and access it quickly. This is what indexers do.
Why blockchain indexers are needed
Blockchain protocols work thanks to nodes that process transactions, ensure network security, and, most importantly, store copies of blocks in chronological order. Validator nodes are conditionally divided into light ones with a copy of the last blocks and archival ones with an entire blockchain. Users can get on-chain data from their nodes or third-party nodes using the Remote Procedure Call API to request data about the blockchain.
However, nodes and RPC API aren't designed to work with complex searches and queries. For example, a developer can access an operation's details only if they know where to look for them.
Let's try to get data about this transaction using Tezos client and RPC API — opRjkzJxJ1xZaUnBDykGUjrRV8qgHFvchcYnbkkcotS1Y7idCSL.
user:~/tezos % tezos-client rpc get /chains/main/blocks/2283690/operations/3/2
Disclaimer:
The Tezos network is a new blockchain technology.
Users are solely responsible for any risks associated
with usage of the Tezos network. Users should do their
own research to determine if Tezos is the appropriate
platform for their needs and should apply judgement and
care in their network interactions.
{ "protocol": "Psithaca2MLRFYargivpo7YvUr7wUDqyxrdhC5CQq78mRvimz6A",
"chain_id": "NetXdQprcVkpawu",
"hash": "opRjkzJxJ1xZaUnBDykGUjrRV8qgHFvchcYnbkkcotS1Y7idCSL",
"branch": "BLPELRQsDcAbeXzVcKnqtT7XG7qmtcSuleddD6235sCyN4x21q6",
"contents":
[ { "kind": "transaction",
"source": "tzlUEQzJbuaGJgwvkekké6HwGwaKvjZ7rr9v4", "fee": "543",
"counter": "18321546", "gas_limit": "1521", "storage_limit": "@",
"amount": "1500000",
"destination": "tz1dFq5gcAMi6éTAUJarNJeP6DffyjrPXzhid" } ],
"signature":
"sigPWea9tsDXrornNziEMWPeEpFfTkf4YdPz7GmgPDPVXQyKwsrpze7wLIXDgZCglL2aaciMa8J1QHAUr2b9zhrK26kpvv8Jz" }
user:~/tezos %
The highlighted part at the top of the screenshot is the command we used:
tezos-client rpc get /chains/main/blocks/2283698/operations/3/2
The numbers in the command mean the following:
- 2283698 — the level of the block in which the operation took place.
- 3 — the index of the operation's source type. "3" means the user initiated it.
- 2 — the index of the operation in a particular block.
To get the details of a specific operation, we need to know its location in the blockchain: when it was included, what operation type table it was written in, and its number in that index. To know it, we need to check all blocks in turn for the presence of the specified hash, which is very slow and ineffective.
Indexers simplify the task of getting the data you need from the blockchain. They request whole blocks from public nodes and write them to their databases. Then indexers create indexes—-additional data structures optimized for fast data retrieval that store either the data or a link to the corresponding place in the central database. When searching for any data, the indexer looks for it in the corresponding index, not in the central database. For even faster searching, some indexers don't store all data in one table but create separate tables for any valuable data.
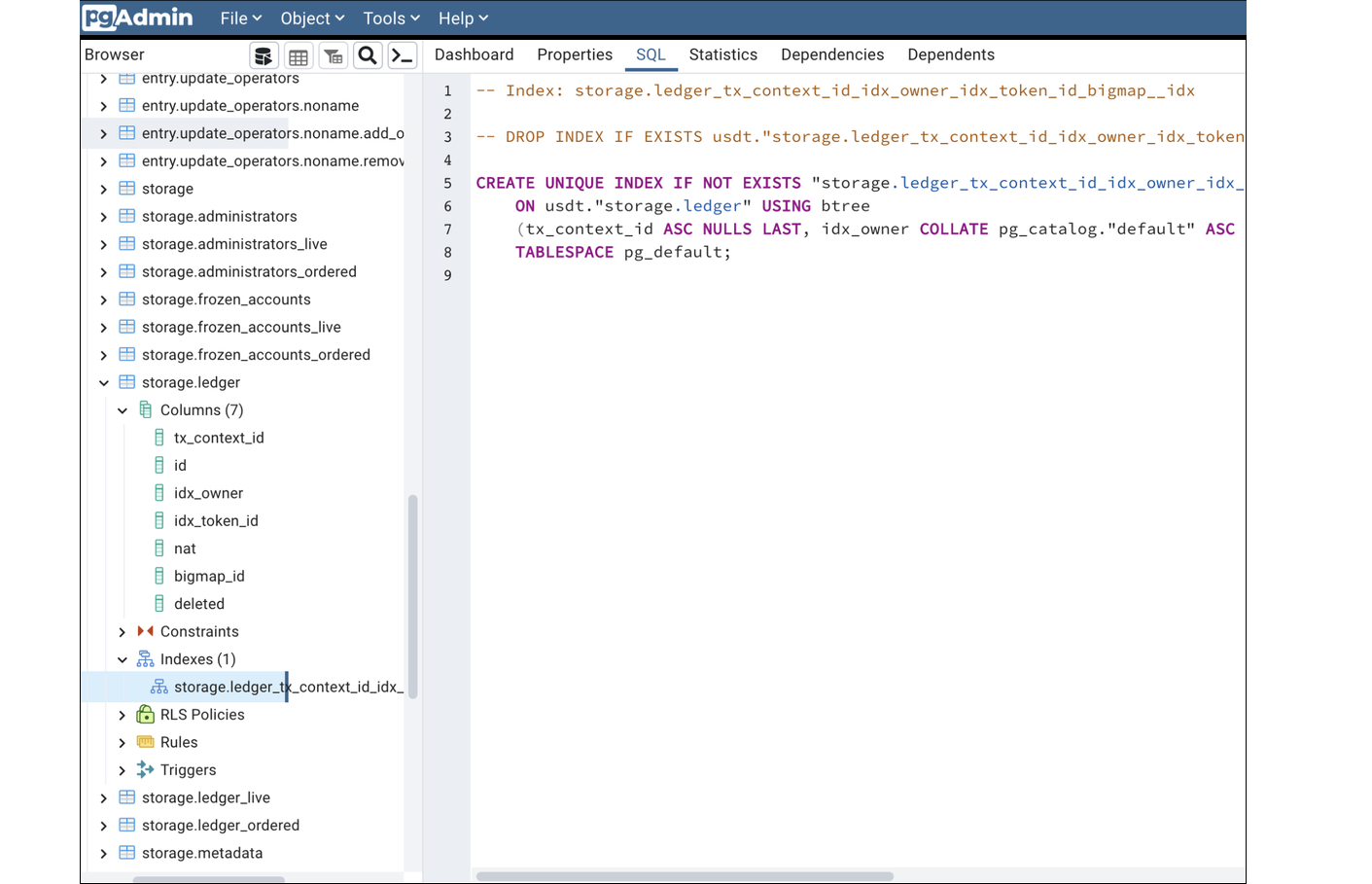
Here is a USDT contract indexed with Que Pasa. It made tables for every entry point and big_map in the contract and an index for every table. It is an efficient way to fetch data. For example, the execution of a query to find a balance of a random USDT holder took only 0.064 milliseconds.
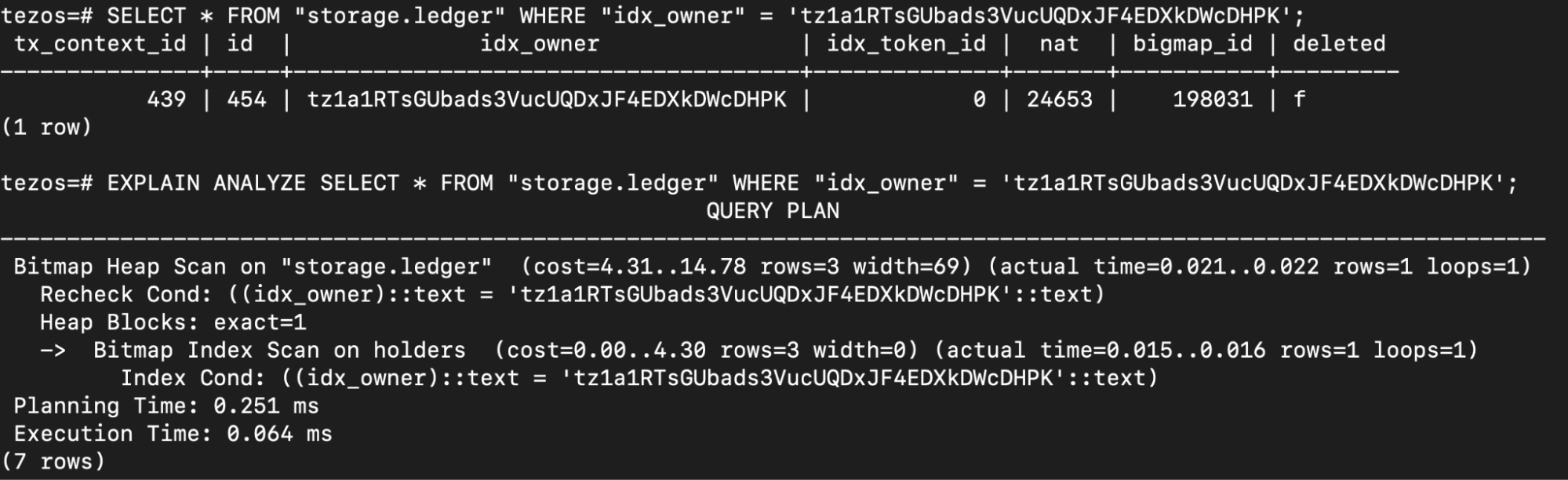
The exact list of tables, indexes schemas, and command syntax depends on the indexer and database it uses. While using TzKT, a query for a USDT balance will look like this:
https://api.tzkt.io/v1/tokens/balances?token.contract=KT1XnTn74bUtxHfDtBmm2bGZAQfhPbvKWR8o&account=tz1a1RTsGUbads3VucUQDxJF4EDXkDWcDHPK
Let's look at the different parts of this url:
https://api.tzkt.io/v1/: link to TzKT APItokens/balances: the path to the table with token balances?token.contract=KT1XnTn74bUtxHfDtBmm2bGZAQfhPbvKWR8o: first search filter, where we specify the contract address we need&account=tz1a1RTsGUbads3VucUQDxJF4EDXkDWcDHPK: second search filter, where we specify holder address
In addition to search speed, indexing has another advantage: the ability to modify indexing rules. For example, TzKT provides an additional index, where each Tezos FA1.2 and FA2 token has its internal id. So instead of comparing relatively long contract addresses, it will compare small numbers and retrieve data even faster.
staging.api.tzkt.io/v1/tokens?id=85
[{"id":85,"contract":
{"alias":"kUSD", "address":"KT1K9gCRgaLRFKTErYt1wVxA3Frb9FjasjTV"},"to
kenId":"0","standard":"fal.2","firstLevel":1330112,"firstTime":"2021-
02-04T05:43:23Z","lastLevel":2667753,"lastTime":"2022-08-
30T20:13:29Z", "transfersCount":323378,"balancesCount":9030, "holdersCo unt":3854,"totalMinted":"31442022884393231737144909","totalBurned":"2 9832264735683726828828184","totalSupply":"1609758148709504908316725", "metadata":{"name":"Kolibri USD","symbol": "kUSD","decimals":"18"}}]
There are two types of blockchain indexers: full and selective.
Full indexers process and write all data from blocks, from simple transactions to validator's node software versions. Blockchain explorers commonly use them to provide users with advanced blockchain analytics and allow them to search for any type of on-chain data. Also, those who host full indexers often offer public APIs that other projects can use without hosting the indexer themselves.
The best examples of full indexers with public APIs are TzKT and TzStats. They allow you to find almost any information that once got into the Tezos blockchain.
Selective indexers store only selected data. Usually, they find their use in projects requiring only specific on-chain data: active user balances, balances of their smart contracts, and NFT metadata. A custom selective indexer can be optimized for fast execution of specific project queries and also needs less space and resources to maintain.
Popular selective indexers like Que Pasa and frameworks like DipDup and Dappetizer can be used to build the indexer you need. For example, Teia.art and other NFT marketplaces use their indexers based on DipDup, optimized for working with NFTs.
What data can be obtained through a blockchain indexer
The exact list of queries and filters depends on the selected indexer. But in general, from a full indexer, you can get information about:
- Account: tez balance, transaction history, address type, and status like "baker" or “delegator,” etc.
- Block: header, content, and metadata like address and socials of the baker who made the block.
- Contract: description, entry points, balance, code in Michelson, storage, and the content of a specific big map.
- Bakers and delegators: who earned how much, who endorsed a particular block, how much users delegate.
- Protocol: what cycle is now, what is on the vote, how many tez are in circulation.
We took some interesting and simple examples for calling BetterCallDev and TzKT indexers. Follow the links and paste your address instead of tz1…9v4 into the address bar to get data about your wallet:
- fxhash NFTs you own. The fxhash contract address filters the query, so try to change the address to see your NFTs from other marketplaces.
- Your balance history in tez. Nodes and indexers display balances without decimals, and ""balance": 500000" means only five tez.
- List of FA1.2 and FA2 token transfers where you were the sender. Change "from" to "to" in the query to see the list of transfers where you were a recipient.
Where Indexers Are Used
Many applications that work with on-chain data use an indexer.
The simplest example of working with an indexer is a blockchain wallet. For example, to display a user's token balances, Temple Wallet queries this data from the TzKT indexer and gets tokens' tickers and logos from the contract metadata.
Try it yourself: Go here and replace tz1...9v4 with your wallet address to see which tokens you have. This is the same query to TzKT API that Temple uses: '/tokens/balances' in constants getTokenBalances and getNFTBalances.
In the same way, Temple Wallet receives transaction details and displays NFTs, delegation rewards, the value of your tokens, and other data. For different queries, it uses various sources. For example, it requests the XTZ price from Coingecko.
Other blockchain applications work similarly:
- Decentralized exchanges' websites use indexers to obtain historical data on the balances of each pool, transactions with them, and the value of tez. Based on this data, they calculate the volume of transactions in tez and dollars, as well as the historical prices of tokens in dollars.
- NFT marketplaces' websites index transactions with their contracts to display new NFTs, transaction history, and statistics of the most popular tokens.
- Blockchain explorers display data from all blocks with the help of indexers and allow users to find anything, like operation details by its hash. Thanks to this, users can find the information they need in a user-friendly graphical interface. Browsers also run public APIs that other projects use.
Self study
Let's say you plan to launch a DeFi dashboard that will display the user's token balances: tez, stablecoins, fungible tokens, and NFTs. Think about how you would implement this based on what you have learned about blockchain indexers.
Solution
The simple way to do this is to make a list of all token smart contracts addresses and then run an indexer to store the contents of their storage in a database. Then you could run queries to get all balance records about the selected address. TzKT does it this way and even has a specific API endpoint:
https://api.tzkt.io/v1/tokens/balances?account=tz1UEQzJbuaGJgwvkekk6HwGwaKvjZ7rr9v4
Using an indexer is not necessary, but the alternative — to use public RPC nodes and fetch data directly from the blockchain — is much more complicated. Token balances can be obtained by reading big_map contracts that store balance records. First, you would need to get the hash of the user's address in script-expression format. To do this, run the command
octez-client hash data '"{address}"' of type address
user:~ % tezos-client hash data '"KT1Gxqznvqznkd3fQRRf95ftYByLpE8uqfTg"' of type address
Raw packed data: 0x050a00000016015beddb4e4cc337681090176a860473a7eba9c4a000 Script-expression-ID-Hash: exprvD3jLXJyLguSwR7D95ZZORHvahH2jdbBbv83m5yrZzyUFR2pVY
Raw Script-expression-ID-Hash: 0xdee7e7a90d3a74fe619d8c201181230a911d4e0427648cd175b7bab29e64a4d2 Ledger Blake2b hash: G18cCFYnGr9yviP24UTXUXasqYiqx5uC4fbx1nRHkFuT
Raw Sha256 hash: 0x08ebb0f9abe29615e6a6ca128e15b4811a70de097b595de72192dfe72755985b
Raw Sha512 hash: 0x1b4a9ecdc318d7f1fa0f6dd67f1ff11dfcfda7530667f07ebcd0301f96fb9377cedcac567bfe36ab60c976b
009b99c791eee28917b3bbe7a10ea73e24c3c288f
Gas remaining: 1039995.417 units remaining
Then you would need to find out the big_map id of the token contracts, pools, and farms you want to map. For example, Kolibri USD (kUSD) stores user balances in a big_map with id 380.
octez-client get element exprvEJ9kYbvt2rmka1jac8voDT4xJSAiy48YJdtrXEVxrdZJRpLYr of big map 380
user:~ % tezos-client get element exprvD3jLXJyLguSwR7D95ZZoRHvahH2jdbBbv83m5yrZzyUfR2pVY of big map 380
Pair {} 784604439440371
user:~ %
That is, to find out the balances of FA1.2 and FA2 tokens, you need to collect in advance the id of the necessary big_map contracts of tokens, and in turn, ask them for values by address.
See how much more complicated it is to query data from blockchain rather than to use indexers.
How to Use the TzKT API in a Simple Project on Tezos
Previously, we talked about how indexers work and showed a couple of examples. Now let's explain how to use them for real-life tasks. First, let's make a simple website for displaying the balance of an address, then a more complex dashboard for displaying liquidity baking data and calculating indicators.
We will use public TzKT and JavaScript with the jQuery library in our examples. Nothing complicated, just one HTML file with a script.
Displaying Address Balance Using the TzKT Public Indexer
The most popular use case for blockchain explorers and indexers is to check the balance of different tokens for a given address. It is convenient when storing cryptocurrencies in a cold wallet: you do not need to connect it to the network again, thus endangering the funds.
We will make a simple page where users can enter their addresses and check the balance in tez. Then we will add the display of token balances and some other information. To do this, we will use the TzKT API.
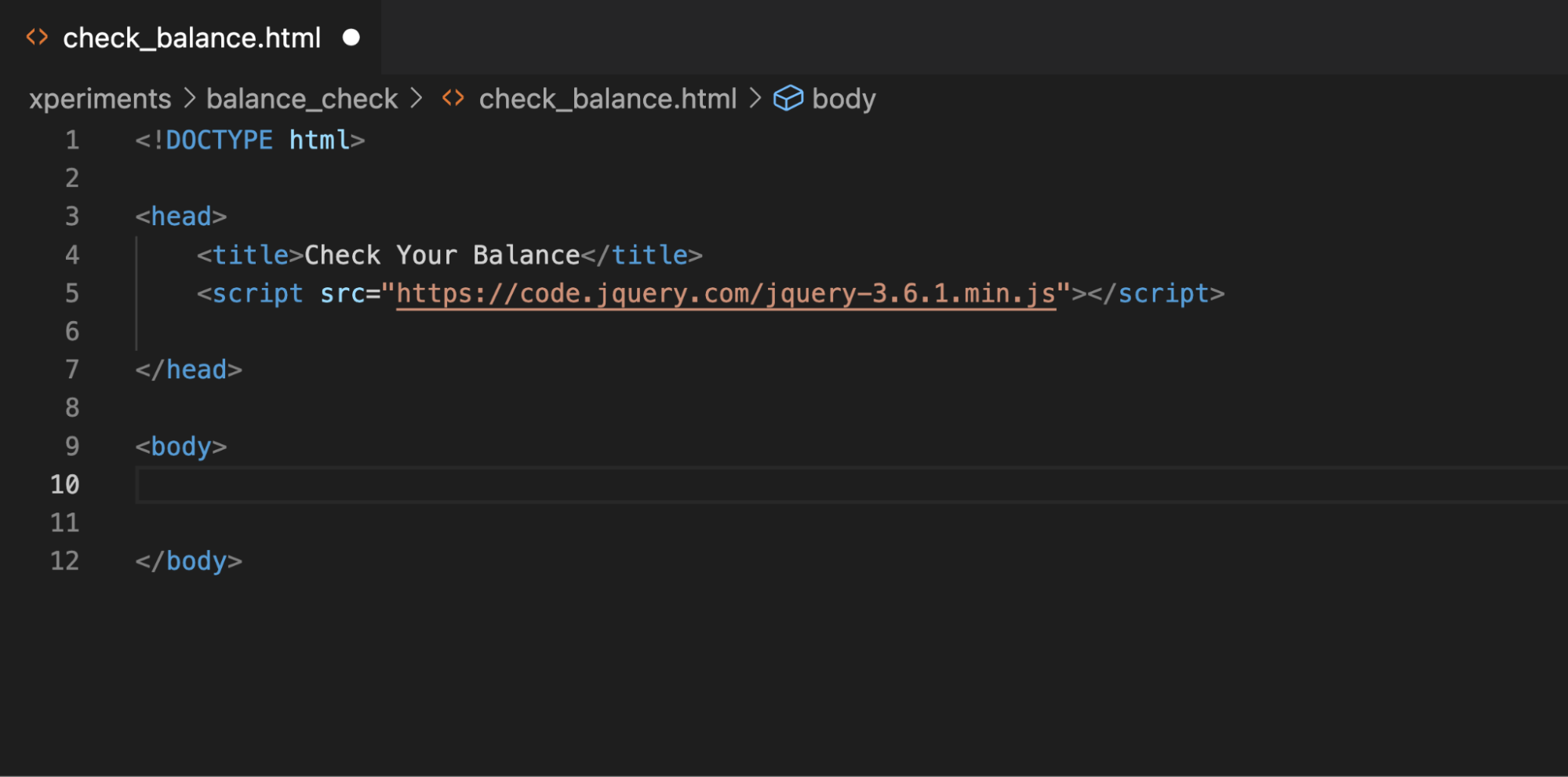
First, let's create an empty HTML file in VS Code (you may use another editor, of course) and add the essential elements: doctype, head, title, and body.
We will use AJAX and the jQuery library to request data via the API and process it. Incorporating a library is simple: just provide a link to it in the script element.
Let's get the balance of our address via AJAX.
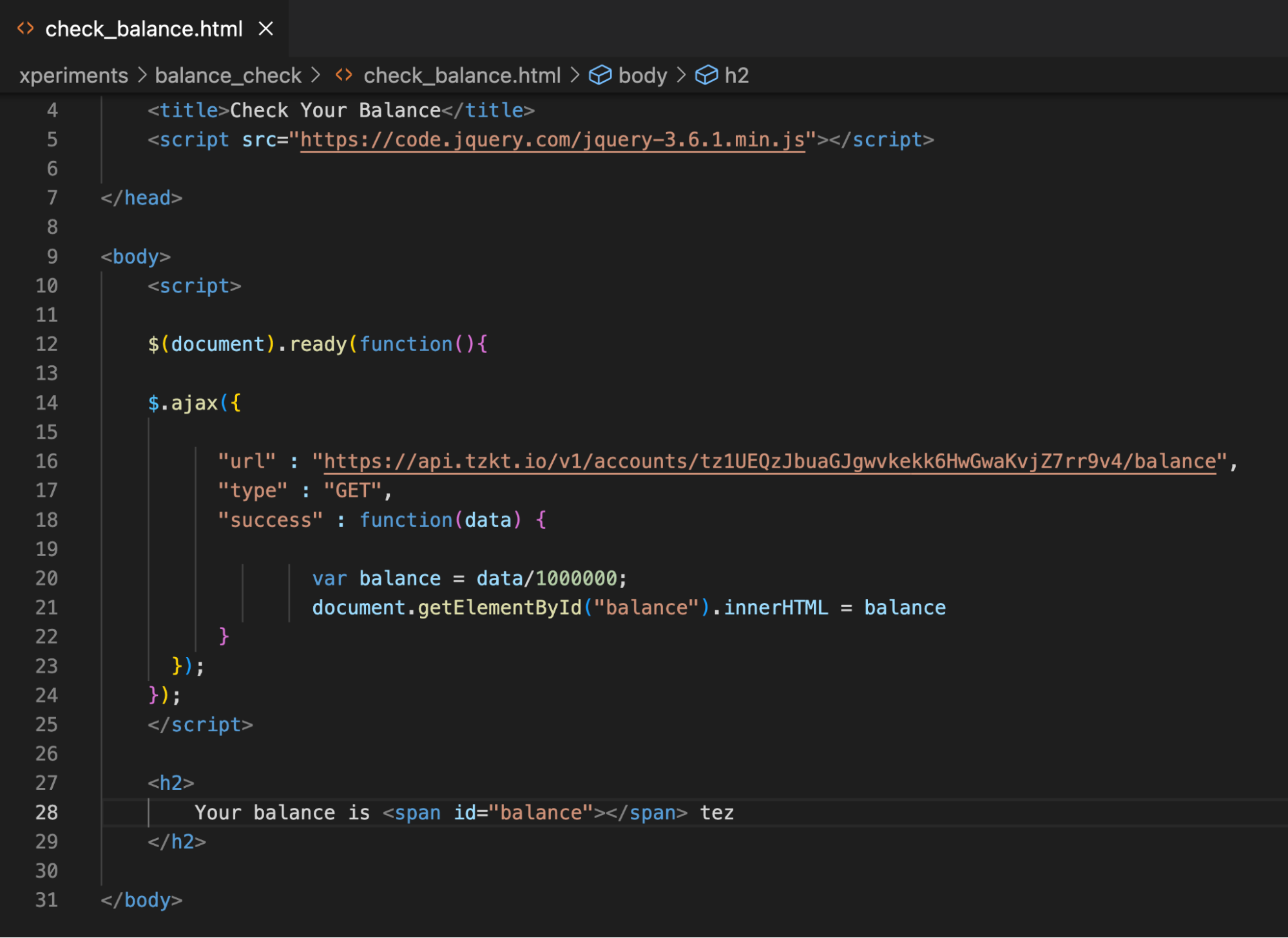
First, we added the $(document).ready() command. It ensures the page is loaded before the scripts are processed.
Then we wrote a request to TzKT using AJAX: in "URL,” the request link to get the balance; in "type," the type of the GET request to get information; and in "success," the function that will process the response.
In the function, we will declare the variable balance, assign the value of the answer (data), and immediately divide it by a million. You must do this because the indexer returns the balance in mutez, millionths of tez.
To use the balance variable in HTML, you need to assign an internal id to this variable. Let's do this with the document.getElementById method.
In the end, we will add a h2 element, in which we will display the balance. To display the variable's value, we use the span element and the id previously assigned to the balance variable.
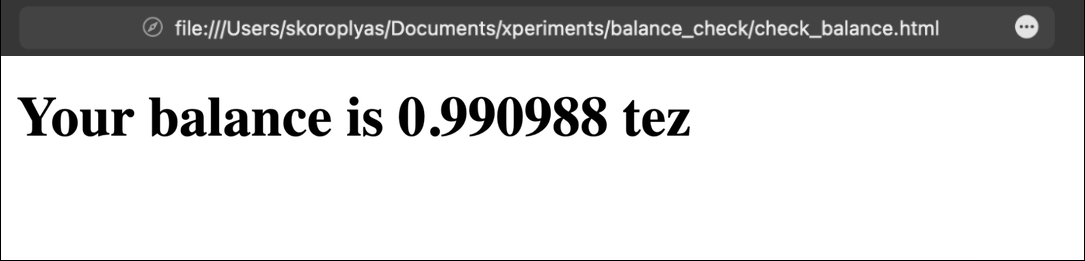
Let's open the page and check the result.
Adding a button and field to check specific address balance
AJAX now sends an API request as soon as the page loads. Let's add a button, pressing which will launch the request.
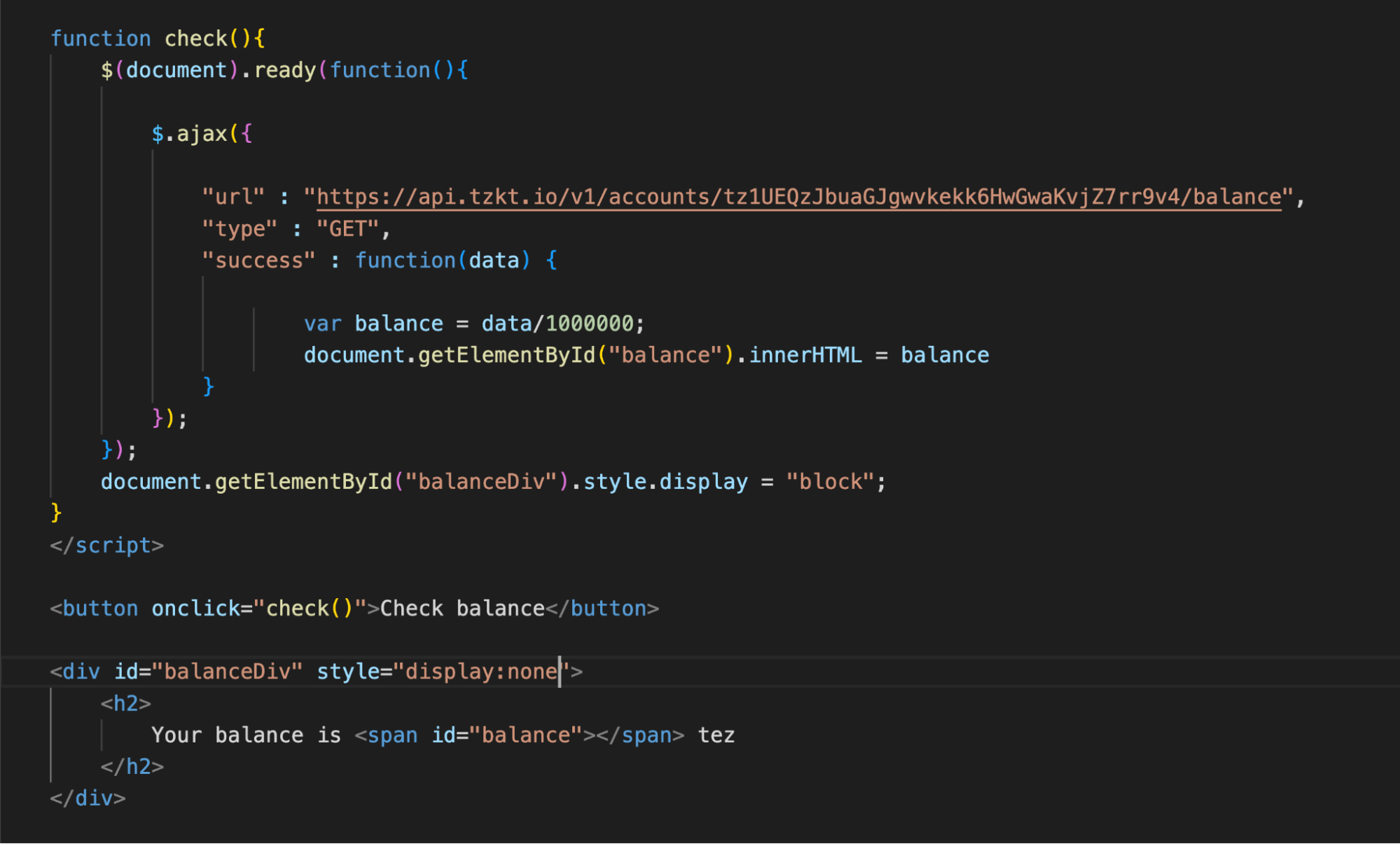
To do this, wrap the h2 in a div element and make it hidden with the style="display:none" parameter.
Let's create a button and add a call to the check function to it, in which we will place the entire request code. At the end of the function, add a change in the display style of the div to a visible block.
Now we need to add a field for entering the user's address and tweak the check() function to insert it into the API request.
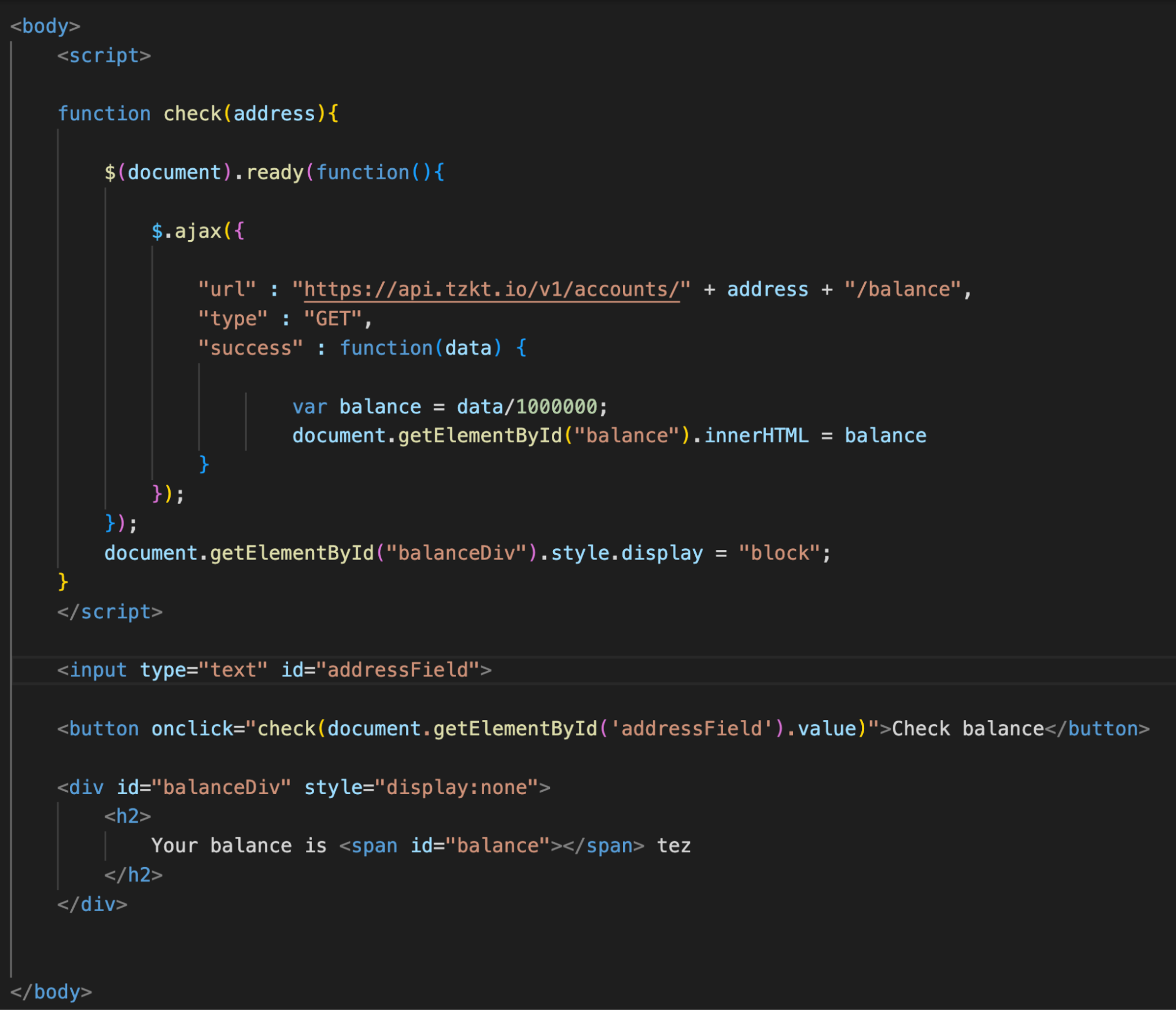
To do this, we did the following:
- Added the address parameter to the check() function.
- Changed the value of the "URL" field. When run, the script will make a valid API request using the received address.
- Added a field for entering an address with an id.
- Changed the button's code so that pressing it would launch the check() function and pass the entered address to it.
Now you can enter any address and, by pressing the button, get its balance in tez.
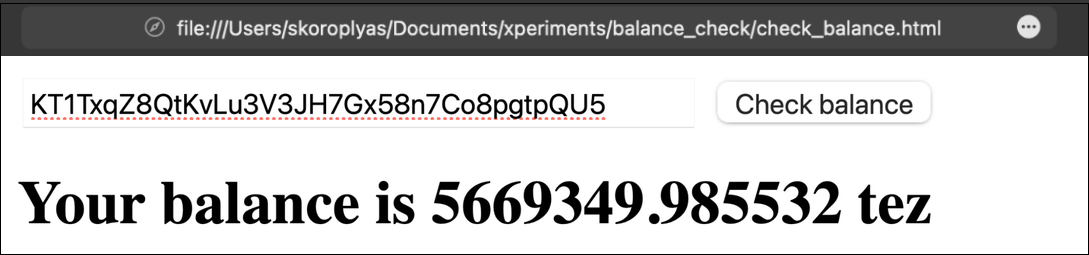
Experiment: take the code of this page, paste it into an empty HTML file, and open it in a browser.
This is a simple example: the TzKT API returns the user's balance as JSON with only one number. The answer does not even need to be further processed: everything works as it is.
When solving real-life cases, however, you will have to work with JSON arrays and carefully read API responses to select the necessary data. The next chapter explores this matter further.
Displaying liquidity baking statistics
That contract with 5 million tez is Sirius DEX, better known as liquidity baking. Here is its contract on TzKT explorer.
Liquidity Baking is Tezos' unique DeFi protocol. Users contribute tez and tzBTC to it to provide liquidity for the exchange, and the Tezos network itself adds another 2.5 tez to the pool in each block. Thus, the balances of liquidity providers in this pool are constantly growing.
Since all liquidity backing data is stored on-chain, we can get it using API requests to public indexers and then calculate the annual yield and other helpful information.
First, we are interested in the balance of Sirius DEX, particularly how many tez and tzBTC the contract holds. We will receive these numbers from the indexer.
We need to calculate how much tez the protocol subsidies per year. Here you can calculate the number of seconds in a year, divide this value by the average block creation time—30 seconds—and multiply by one subsidy.
It remains to find out the current value of assets in Sirius DEX and the value of subsidized tez for the year and divide these values, which would be the annual return or APY.
We are starting a new page. First, let's try to get something simple, like the Sirius DEX internal contract id in the TzKT database.
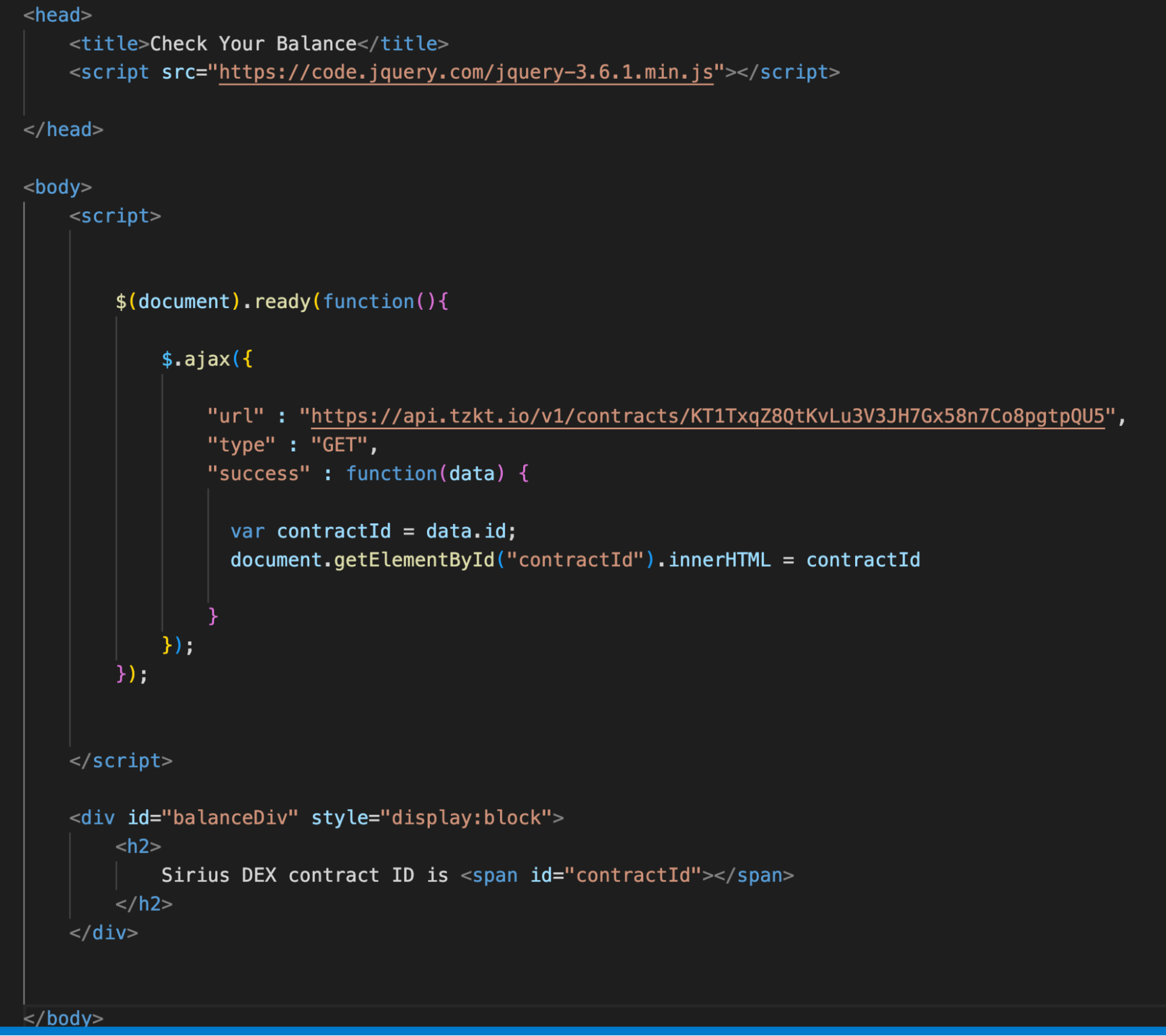
Let's copy the code of the first example and remove the button and the field for entering the address from it. Let's replace the API request URL with https://api.tzkt.io/v1/contracts/KT1TxqZ8QtKvLu3V3JH7Gx58n7Co8pgtpQU5 to get information about the contract from the indexer.
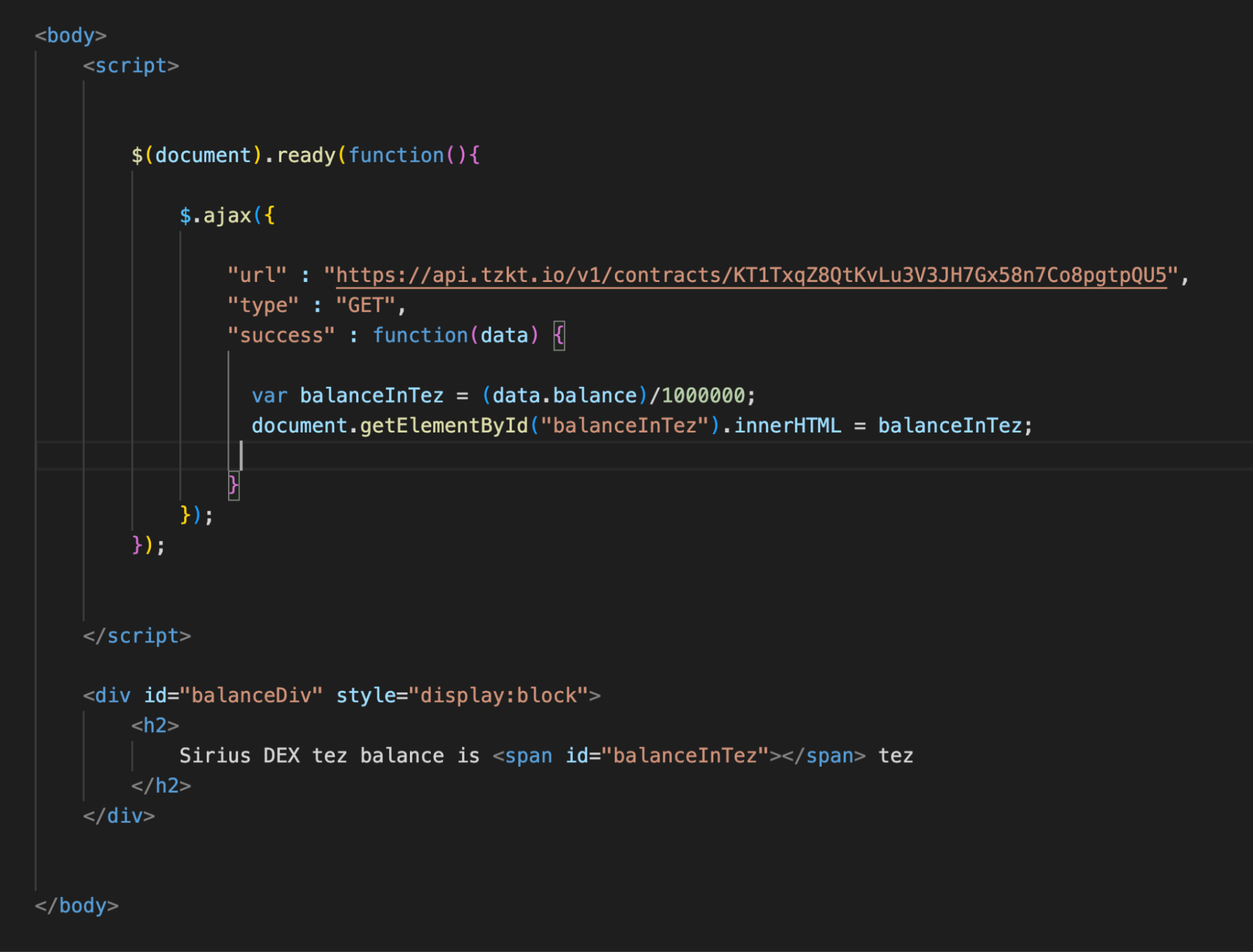
Now it’s time to change the function for data processing. To get specific values, you need to specify the key. In our case, the key is id, and requesting a value using this key will look like var contractId = data.id.
Ultimately, we assign an internal ID, "contractId", to the corresponding HTML element and display it on the page in the h2 element.

We made sure everything worked, so now we can get the data we need: tez and tzBTC balances.
First, we should examine TzKT's response to our API request. It has a balance field in tez, so we can get it without changing the request.
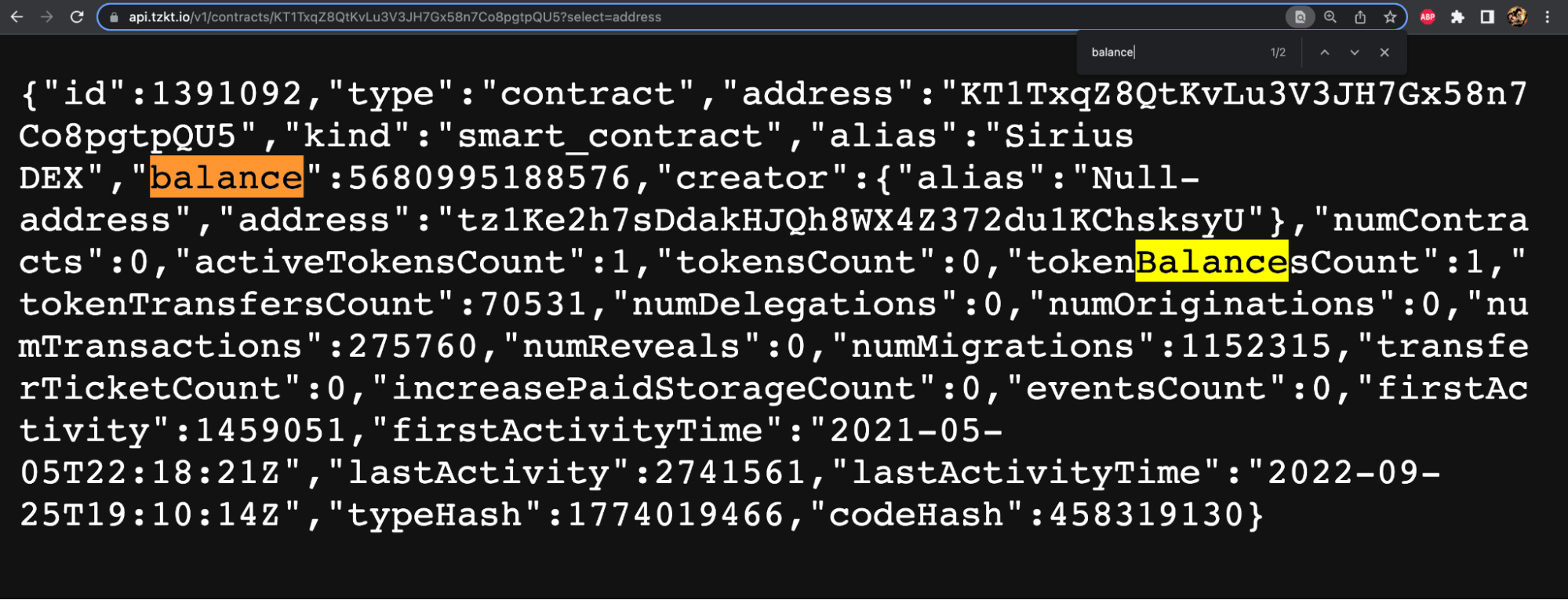
Now, assign the value from the received array to the balanceInTez variable by the balance key.

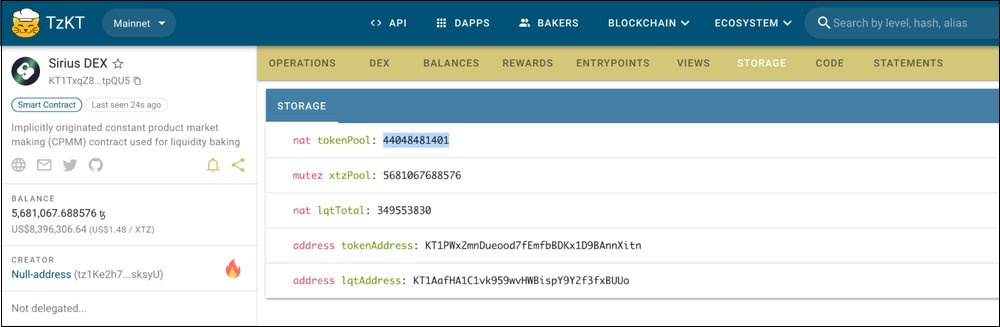
Now we need to get the amount of tzBTC. Let's examine the storage of the liquidity backing contract on TzKT: it shows the amount of tzBTC under the tokenPool key. You can access it by requesting the contents of the storage.
Now we should create another AJAX request. In the URL, we specify the API request for the storage content and assign the value of the corresponding entry, tokenPool, to the balanceInTZBTC variable.
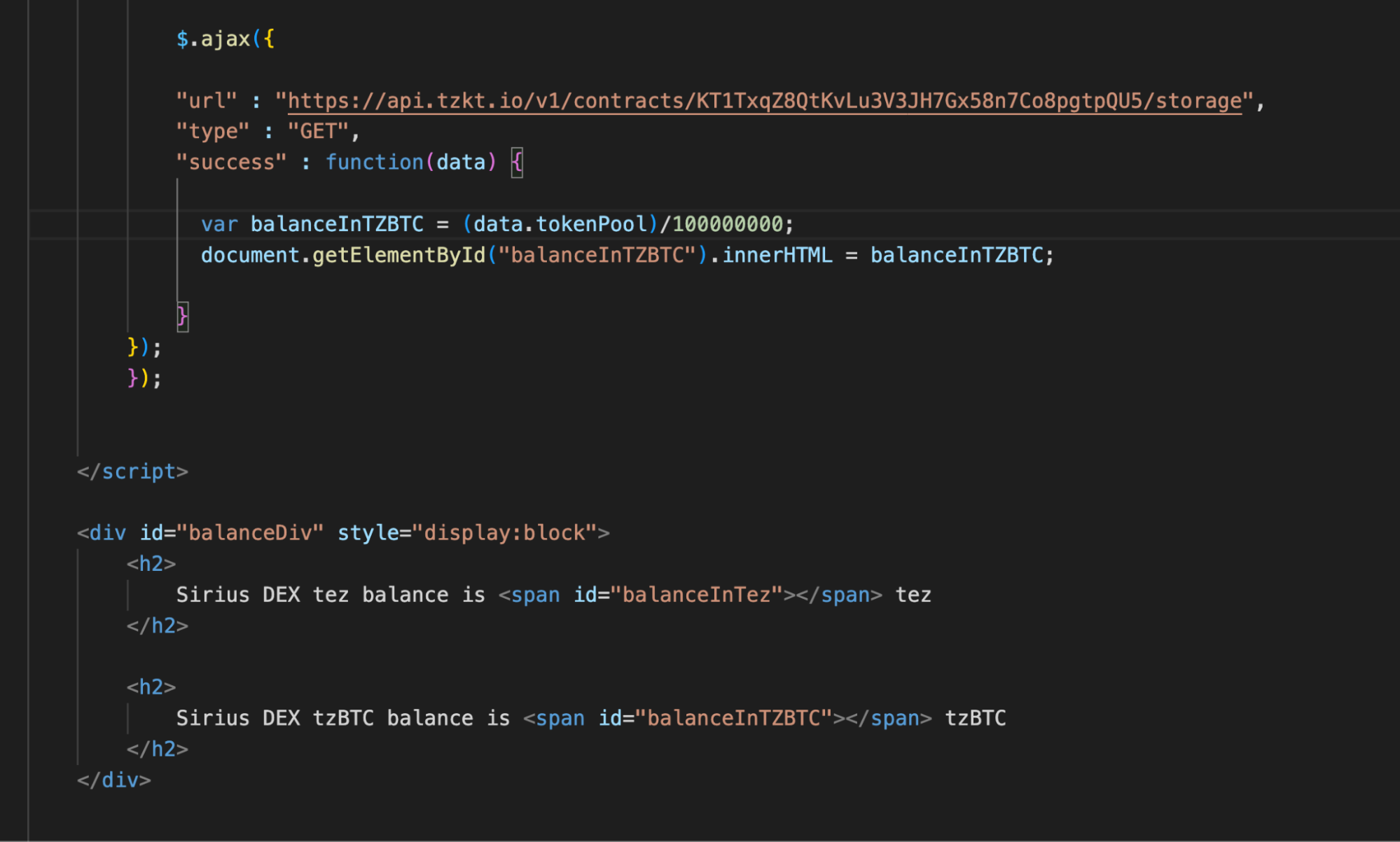
On the page, we will display the balance in tzBTC.

Now it’s time to calculate the subsidies for the year. The average year has 31,556,926 seconds. We divide this value by the block creation time and multiply it by the subsidy amount.
We can get the block creation time and subsidy amount from TzKT at https://api.tzkt.io/v1/protocols/current. They will be referred to as timeBetweenBlocks and lbSubsidy in the response.
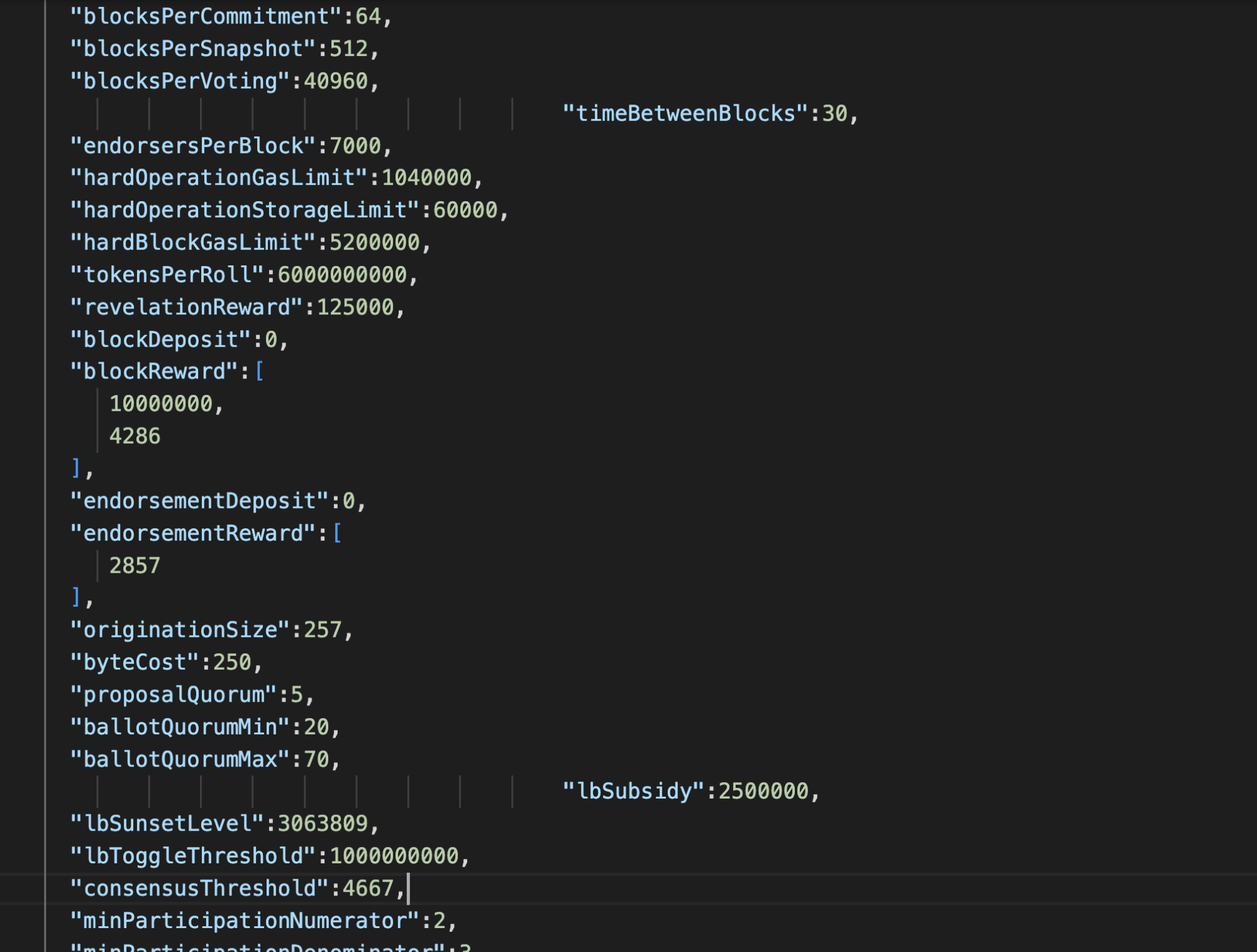
So, we need to get data from two API requests in one function and use it for calculations. But as the variables are local and can't be used in other functions, we need to use nested functions:
- Get the number of tez.
- Write them to a variable.
- Call the function to calculate annual percentage yield (APY) and pass it the number of tez as an argument.
- In the APY function, get the necessary data and make calculations.
- Write the results to variables and assign an ID.
- Return to the first AJAX function and add a variable ID assignment at the end with the amount of tez.
First, let's add a call to the checkTimeAndSubsidy function to get the Sirius DEX balance in tez.
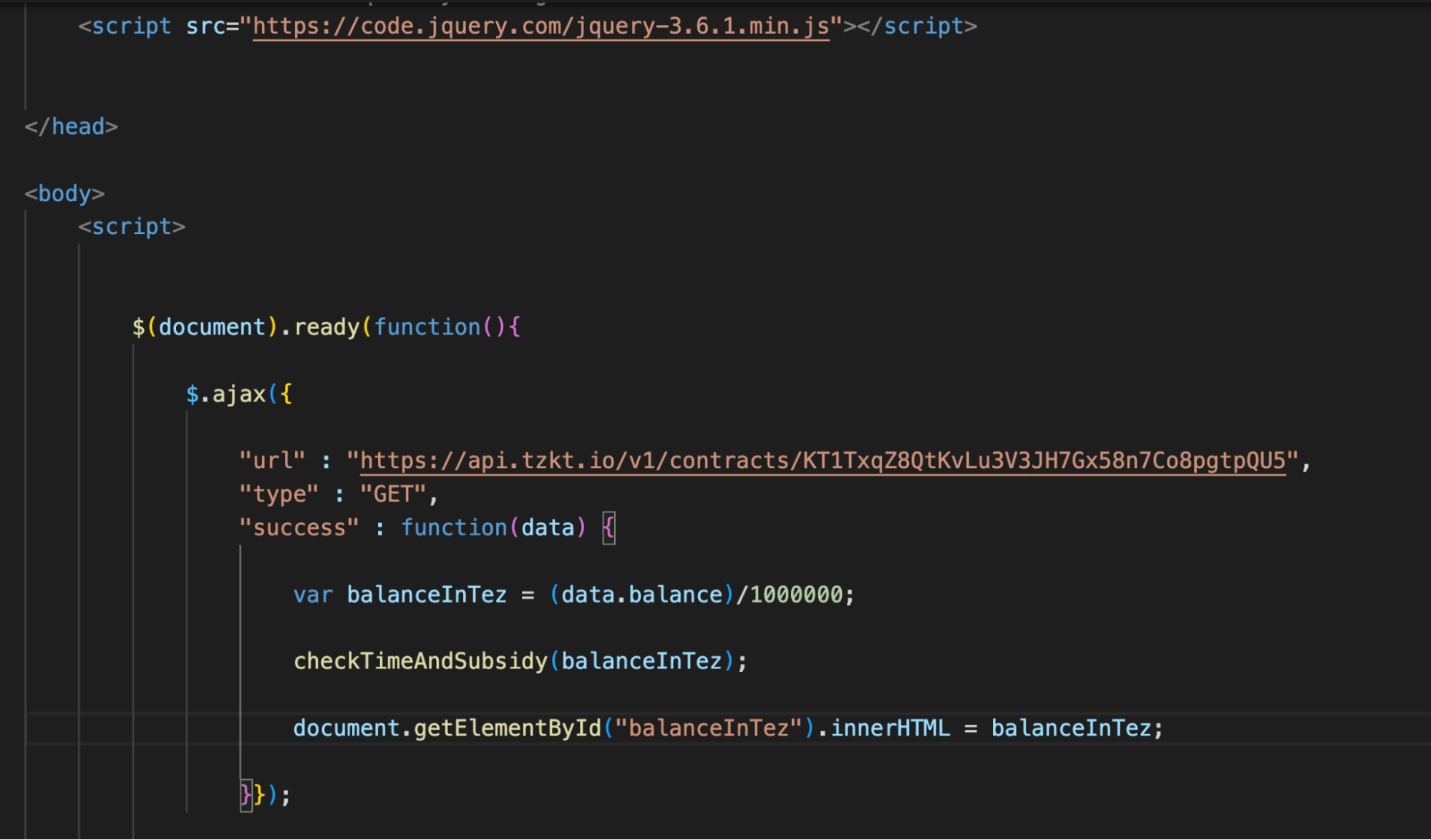
Below, we will declare the same function and add an AJAX call to request protocol data from TzKT.
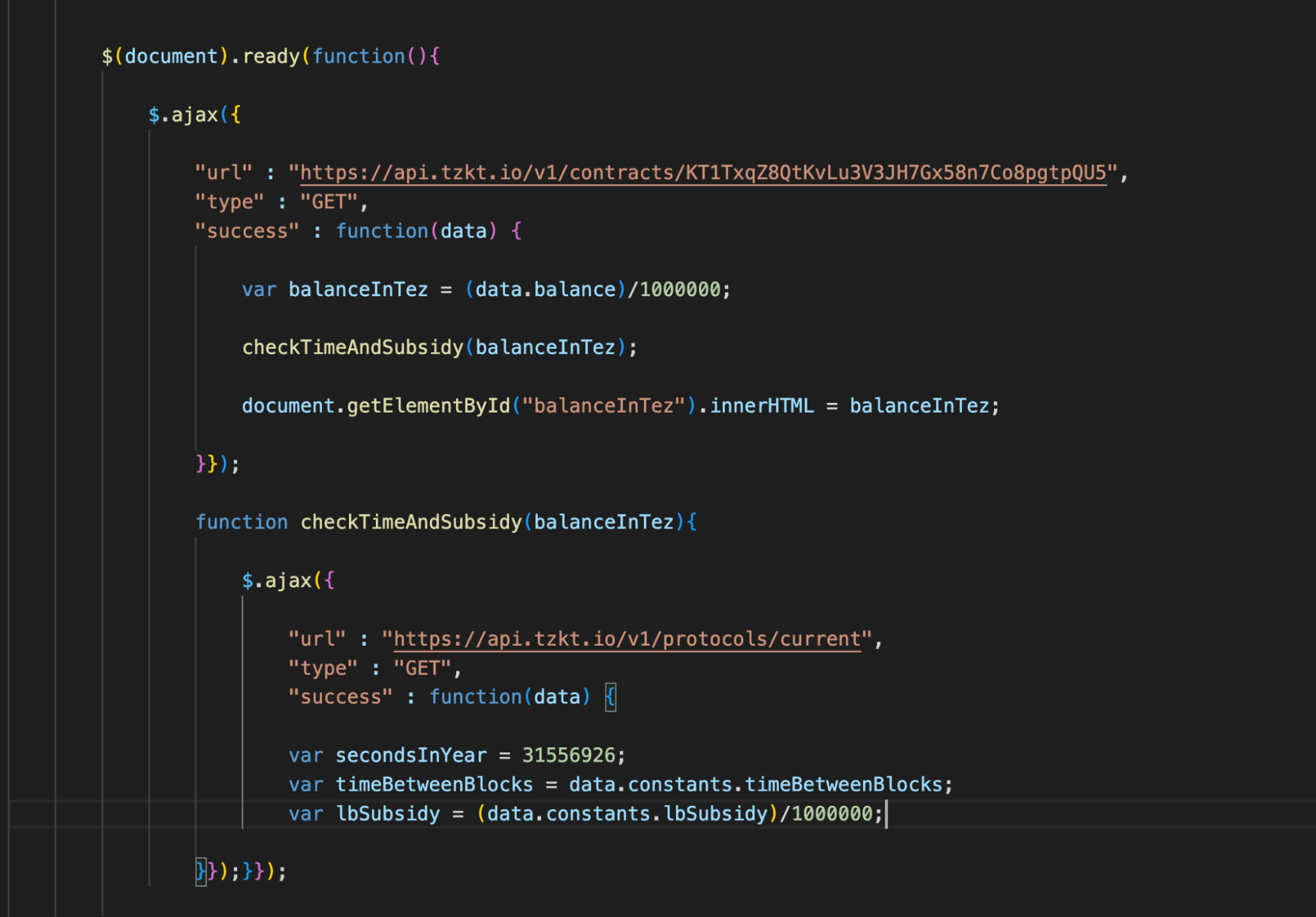
We should assign three new variables:
- secondsInYear: the average number of seconds in a year, in fact, a constant.
- timeBetweenBlocks: block creation time.
- lbSubsidy: Sirius DEX pool subsidy in mutez. We divide it by a million to get the value in tez instead of mutez.
We now have all the data to calculate the annual subsidy and APY liquidity backing.
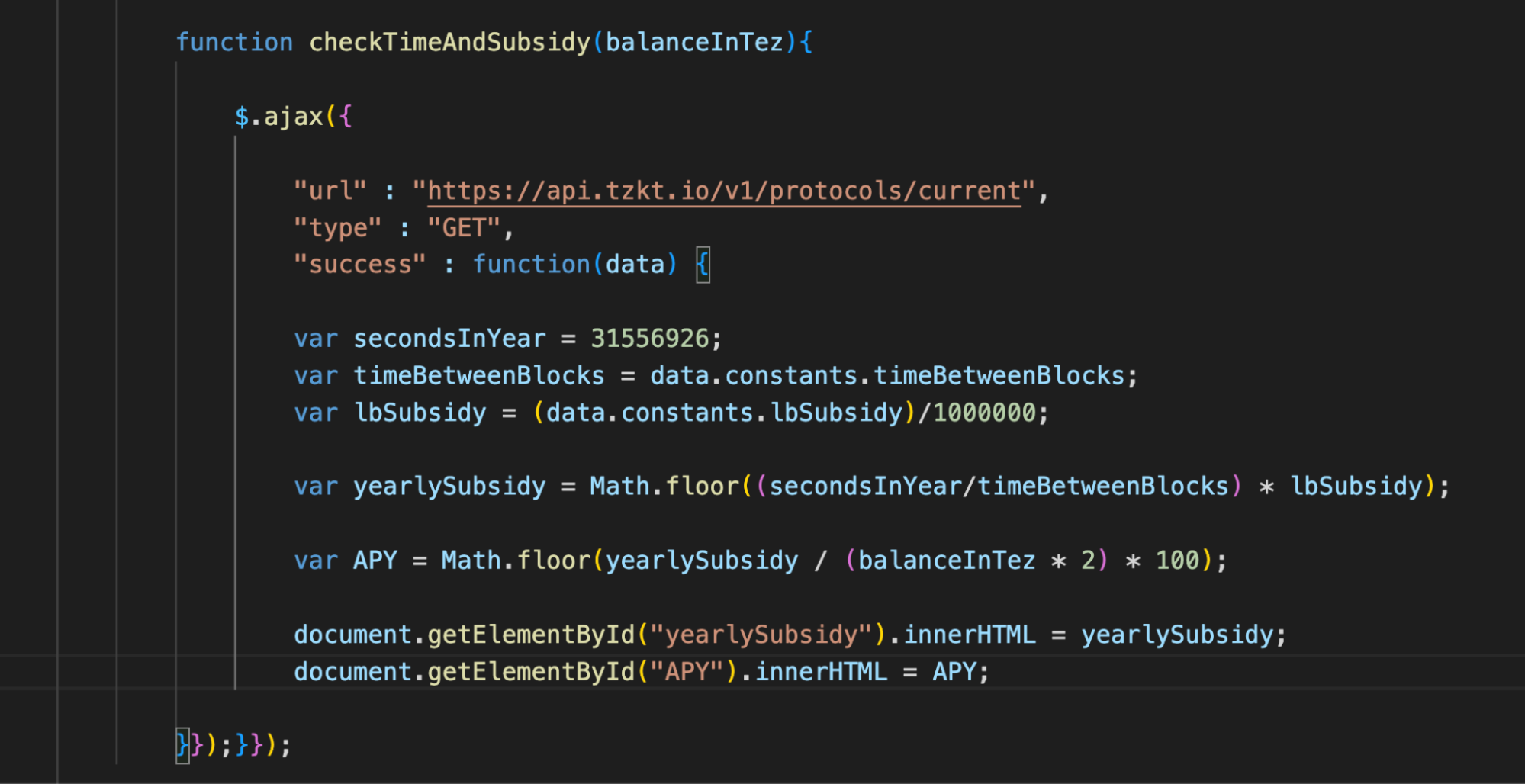
Now we can calculate the necessary values by creating the variables yearlySubsidy and APY.
To calculate APY, it is not necessary to obtain asset prices. At any given moment, the value of all tez in the pool equals the value of all tzBTC. To simplify APY calculation, we assume that the user adds to the liquidity pool not tez and tzBTC, but twice as much tez. His APY would be a share of the yearly subsidy divided by the liquidity he provided. Roughly speaking, APY = yearlySubsidy / (balanceInTez × 2) × 100%.
It’s now possible to give the annual amount of subsidies and APY internal ID values and add them to the page.

Self study
Try to calculate the value of tez in the Sirius DEX liquidity pool.
- Find a smart contract of any liquidity pool with a stablecoin against tez: tez/USDt, tez/kUSD, or tez/uUSD.
- Get the number of tokens in the pool using an API request.
- Divide the number of tez by the number of stablecoins to find the price of tez.
- Multiply the number of tez in the Sirius DEX pool by the resulting exchange rate.
- Add the result to the appropriate line.
Solution
First, check the tez/kUSD contract on an exchange on TzKT. Then examine the storage and find the necessary keys: tez_pool is the amount of tez, and token_pool stands for the amount of kUSD.
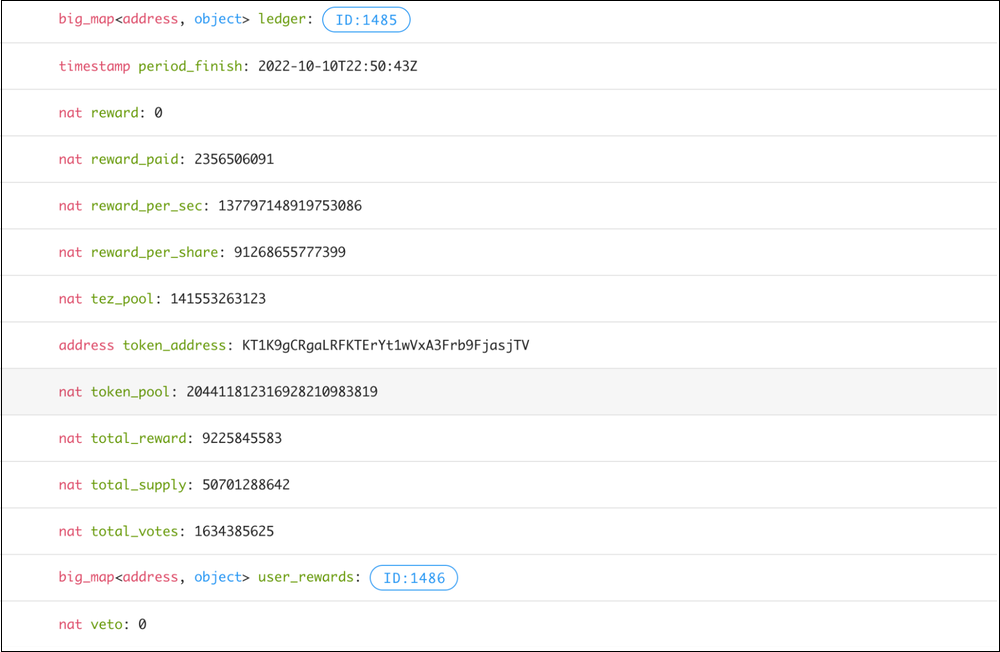
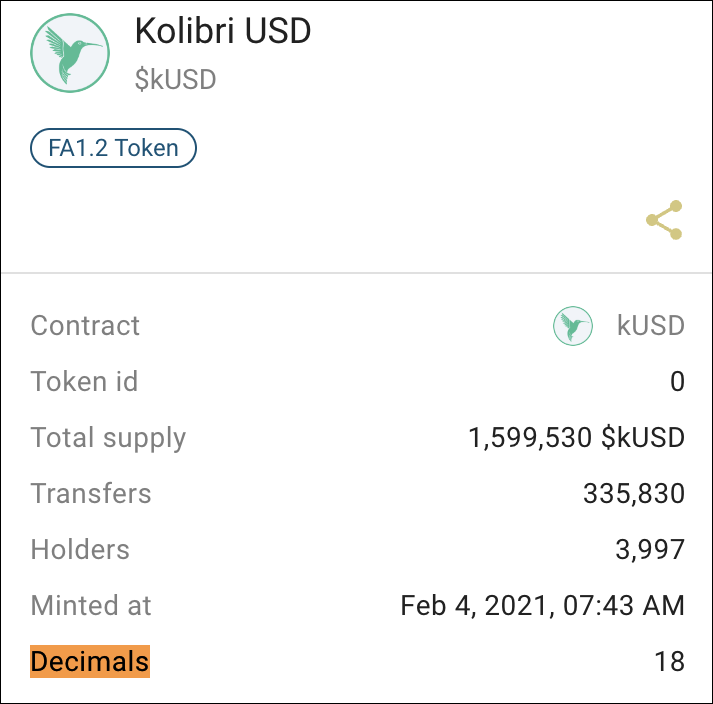
And we need to remember that the token's amount in the contract's storage is a natural number. And to display the actual amount of tokens, we need to divide that number by the corresponding number of decimals written in the contract's metadata. For example, kUSD has 18 decimals, and when we get raw token amount data, we need to divide it by 10^18 to get a human-readable amount.
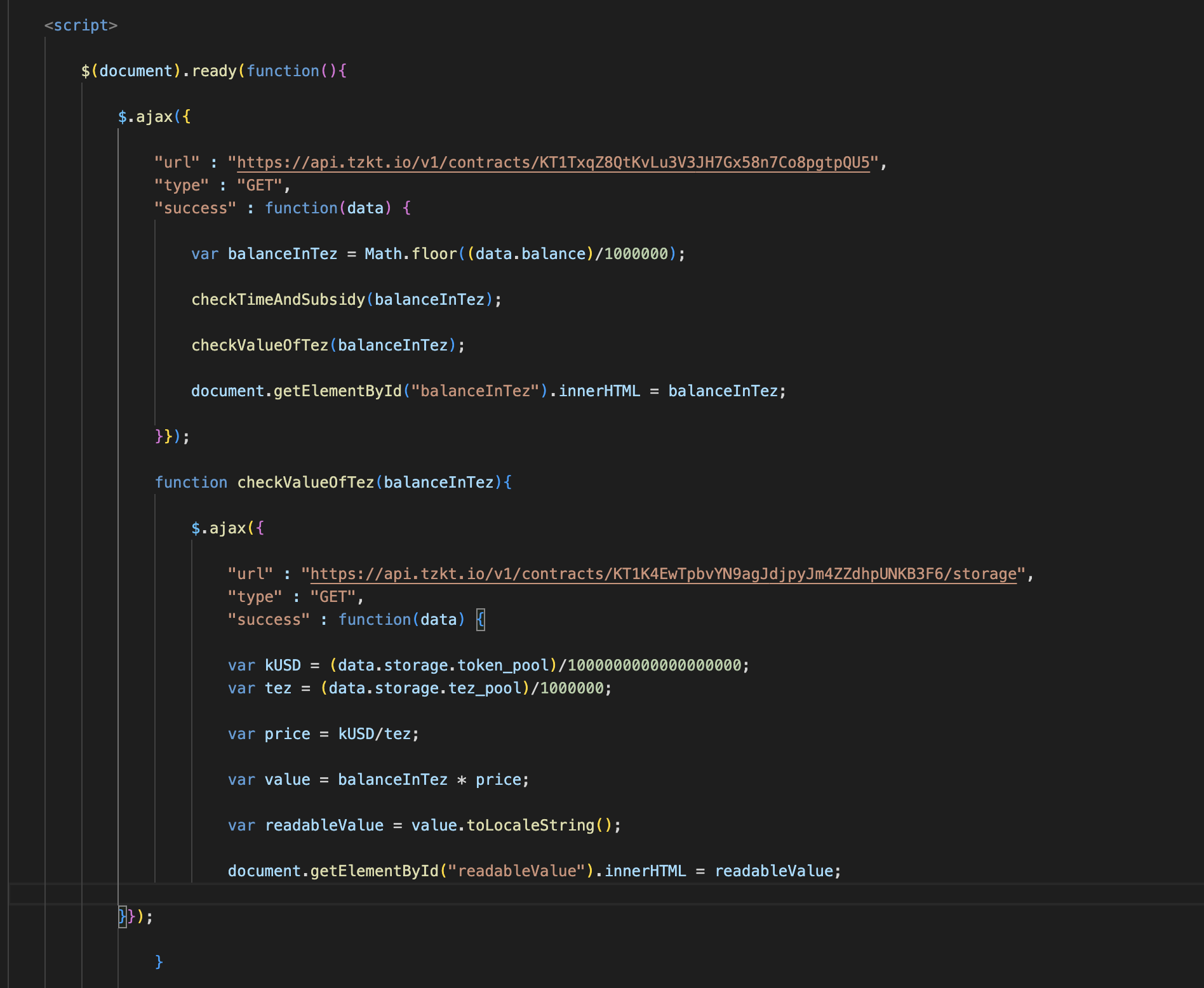
Since we need to know the number of tez in the pool to calculate the cost of all tez, we need to use nested functions. After receiving the balanceInTez variable, we call the checkValueOfTez function with the balanceInTez argument. In this function, we use AJAX to get data from the tez/kUSD pool (remember to divide the number of tokens depending on the required decimals).
Next, we calculate the price of one tez and the cost of all tez in the pool. In the end, we will add the readableValue variable: using the toLocaleString () method, we will add comma separators to the number.
As a result, we get the cost of all tez in the Sirius DEX pool, which we get completely from on-chain data.

This content was created by Tezos Ukraine under MIT Licence. The original version can be found here in multiple languages.